Jeg har problemer med å trekke ut tekst fra fysiske dokumenter og digitalisere den.
Løst av OCR PDF
Problemet
Utfordringen ligger i å trekke ut og digitalisere tekst fra fysiske dokumenter. Dette kan spesielt være tilfelle når man jobber med eldre dokumenter eller tekster fra bilder. Håndskrevne eller skrevne oppføringer gjør disse dokumentene flere ganger vanskeligere å bearbeide og søke gjennom. Feil som oppstår ved behandling av håndskrift, er ofte vanskelige å rette. Derfor kan det være vanskelig å behandle informasjonen effektivt, noe som påvirker produktiviteten og effektiviteten i dokumenthåndteringen.
Skjermbilder
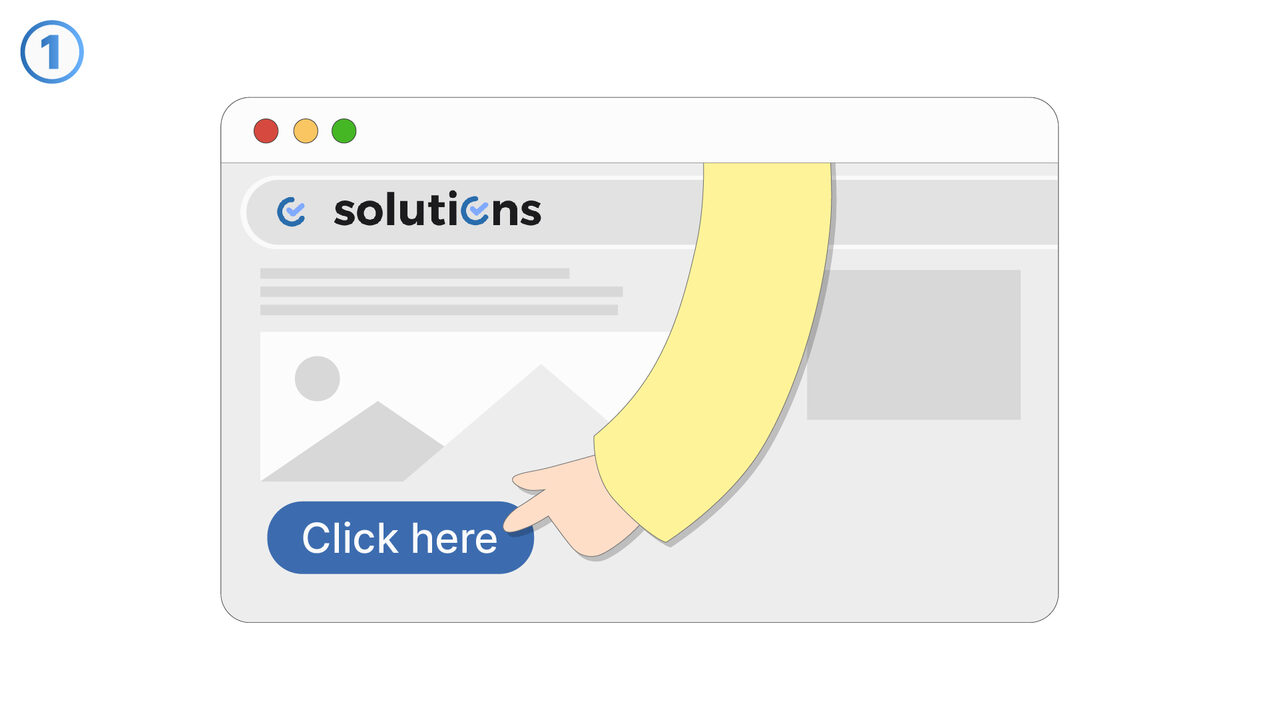
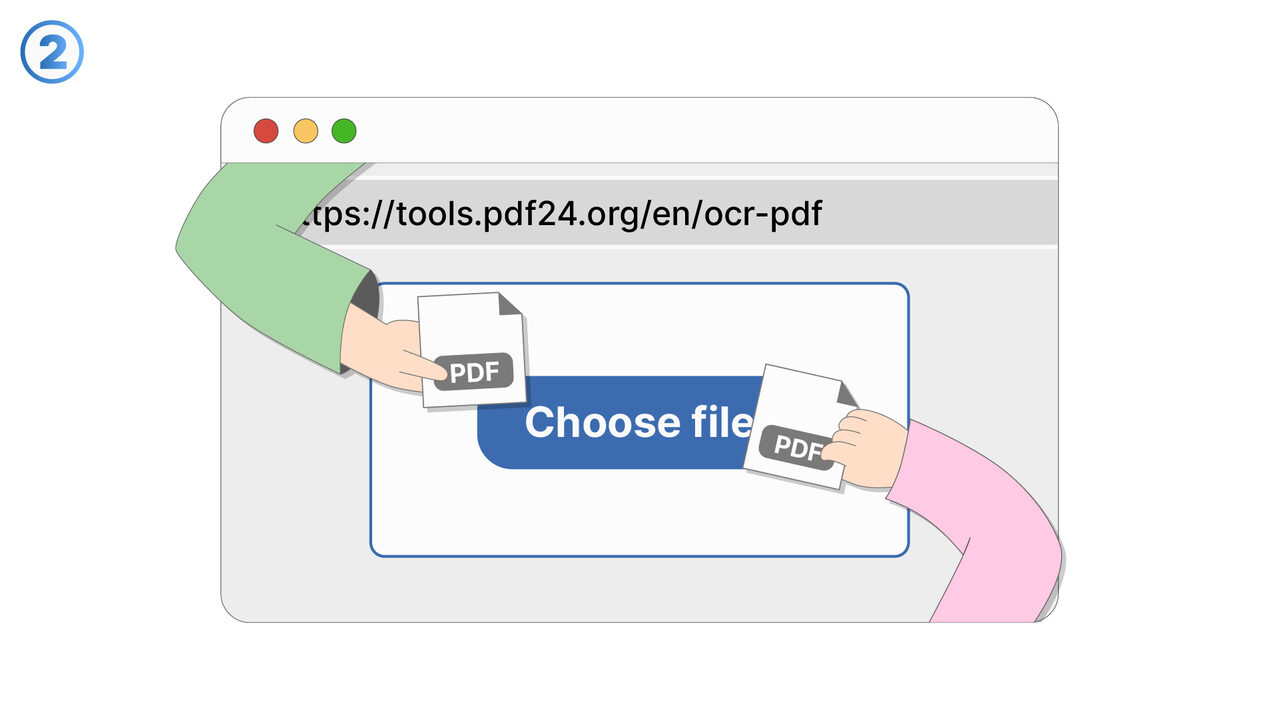
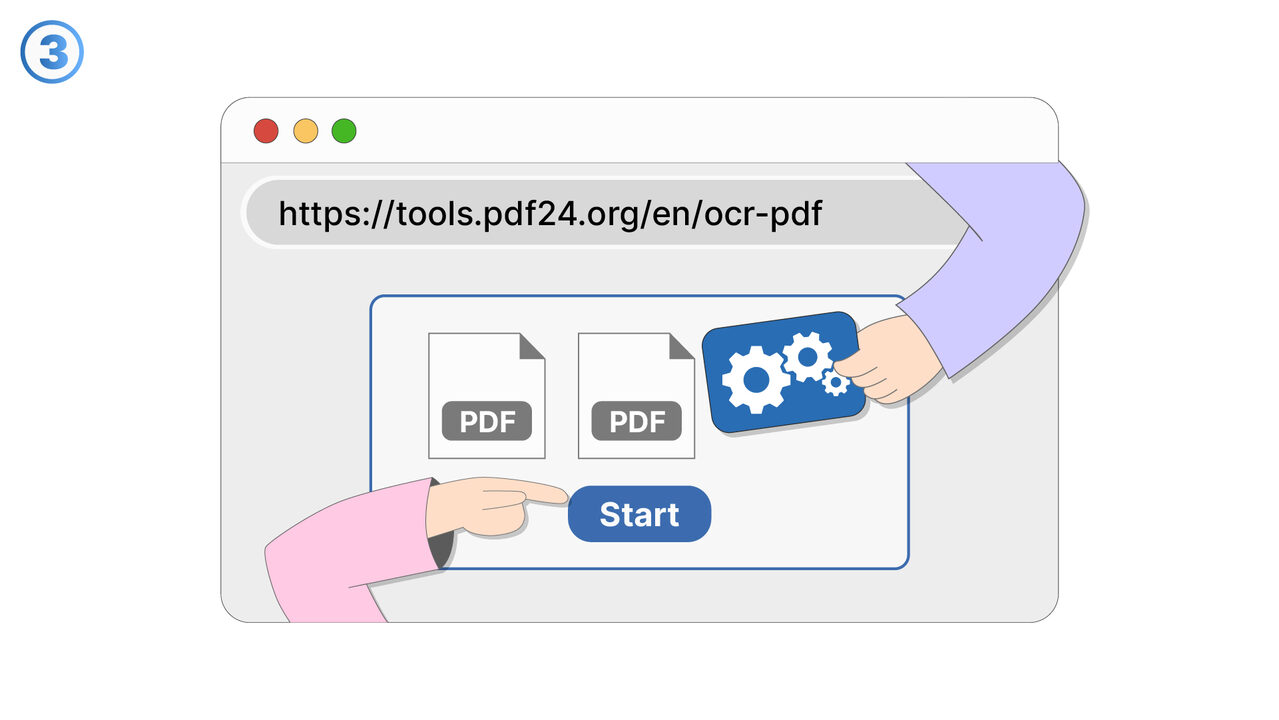
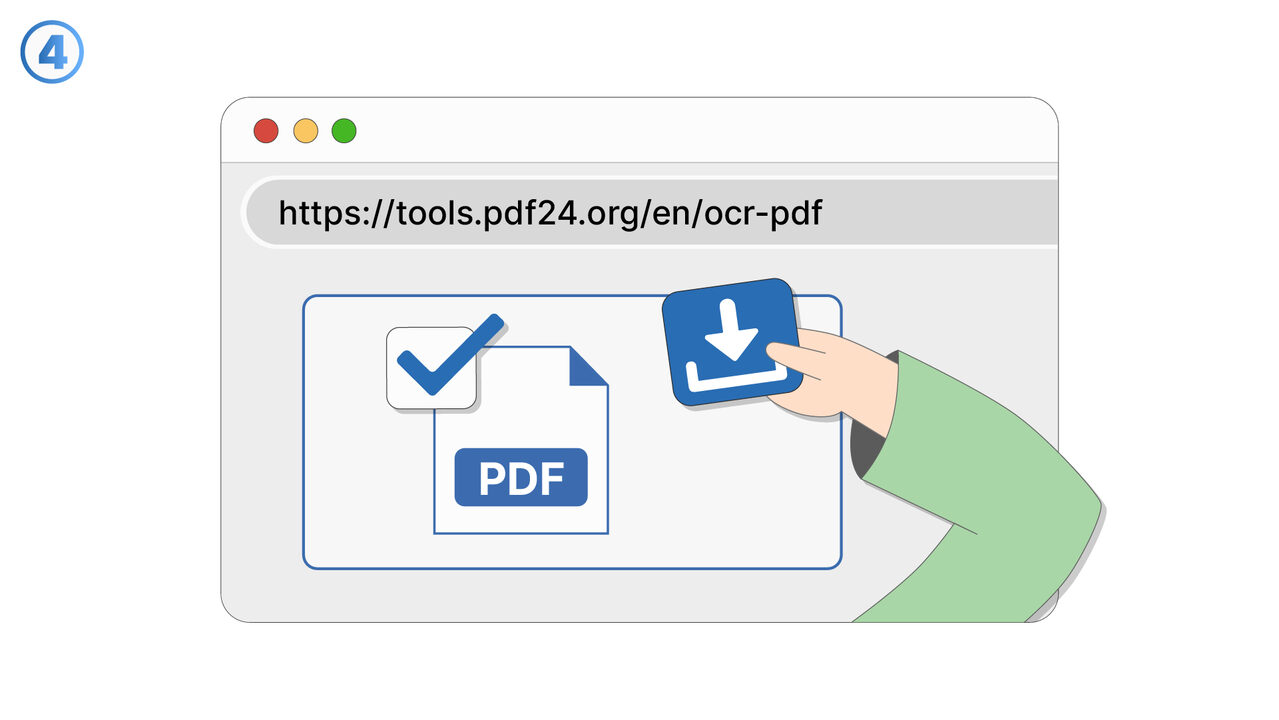
Løsningen
OCR PDF-verktøyet gjør det mulig å skanne fysiske dokumenter og gjenkjenne og digitalisere teksten som er inneholdt der. Med sin optiske tegngjenkjenning er den i stand til å samle inn tekst fra eldre dokumenter eller bilder. Selv håndskrevne eller skrevne oppføringer, som ellers er vanskelige å redigere og søke gjennom, blir omdannet til redigerbar tekst. Eventuelle feil som oppstår under behandlingen av håndskriftene, kan enkelt rettes. Den skannede og gjenkjente teksten blir deretter konvertert til PDF, og blir dermed søkbar og indeksert. Dette øker effektiviteten i dokumentstyringen og bidrar til økt produktivitet. Selv med uklare håndskrifter leverer OCR PDF-verktøyet nøyaktige resultater på grunn av sin høye presisjon.
Ekstern ressurs
https://tools.pdf24.org/en/ocr-pdf
Bruk dette verktøyet som en løsning på følgende problemer
- Jeg kan ikke redigere teksten i PDF-filen min og trenger en løsning for det.
- Jeg har problemer med å digitalisere gamle papirdokumenter.
- Jeg kan ikke søke gjennom innholdet i PDF-filen min og trenger et verktøy for tekstgjenkjenning.
- Jeg har problemer med å kopiere teksten fra et skannet dokument.
- Jeg kan ikke korrigere feil i mine skannede PDF-dokumenter.
- Jeg har problemer med å trekke ut og administrere teksten fra mine fysiske dokumenter.
- Jeg har problemer med å hente ut tekst fra fysiske dokumenter og dele dem digitalt.
- Jeg kan ikke indeksere og kategorisere teksten i min skannede PDF.
- Jeg har problemer med å konvertere teksten fra PDF-er vist som bilder til redigerbar tekst.
Kjenner du en bedre løsning? La oss vite det.
Hvis du kjenner et verktøy eller en tilnærming som kan hjelpe folk med å løse et problem vi ikke har dekket ennå, vil vi gjerne høre om det.