Jeg kan ikke søke gjennom teksten i et PDF-dokument og trenger en løsning for dette.
Løst av Gratis Online OCR
Problemet
Problemstillingen gjelder manglende evne til å søke i tekst i et PDF-dokument. Dette kan føre til problemer når man må søke etter spesifikk informasjon i omfattende dokumenter. Manuell søking i teksten kan være tidkrevende og ineffektivt, spesielt ved lengre og mer komplekse dokumenter. Det er et behov for å finne en løsning som muliggjør søkefunksjonen i PDF-dokumenter og dermed gjør oppgaven enklere og mer tidsbesparende. Dette inkluderer også gjenkjenning og konvertering av tekst i skannede dokumenter og bilder til et søkbart og redigerbart format.
Skjermbilder
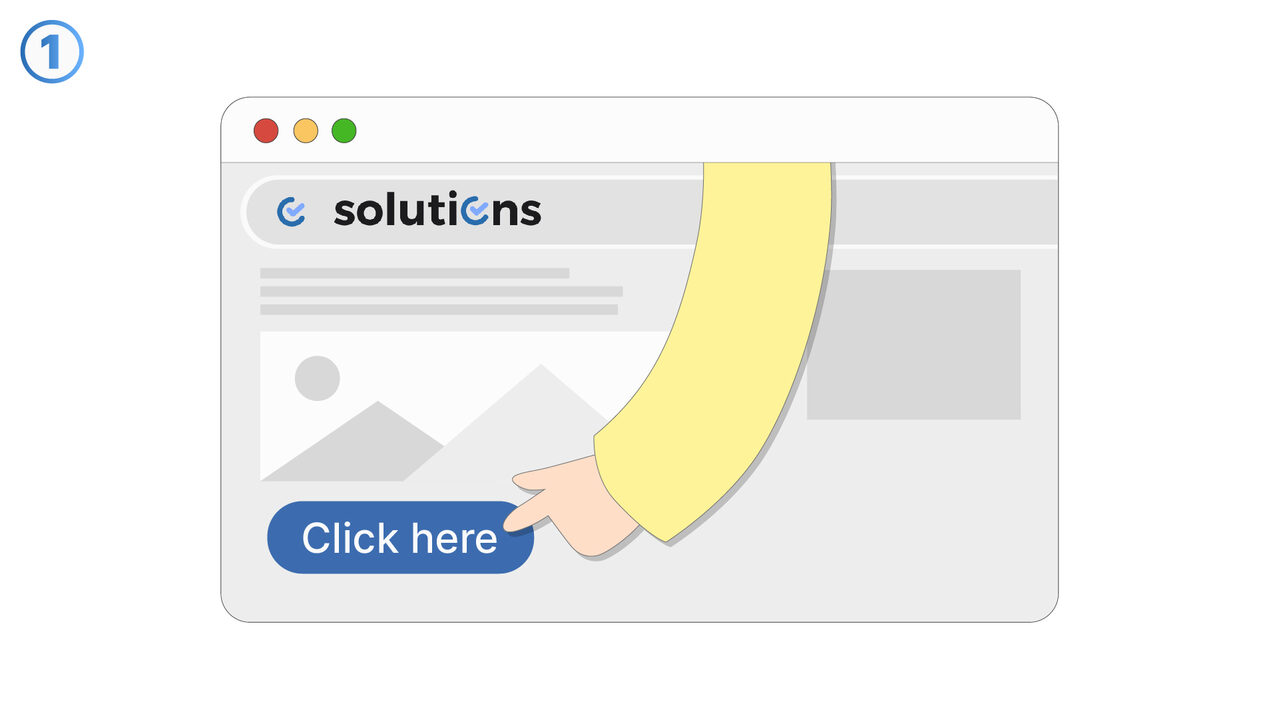
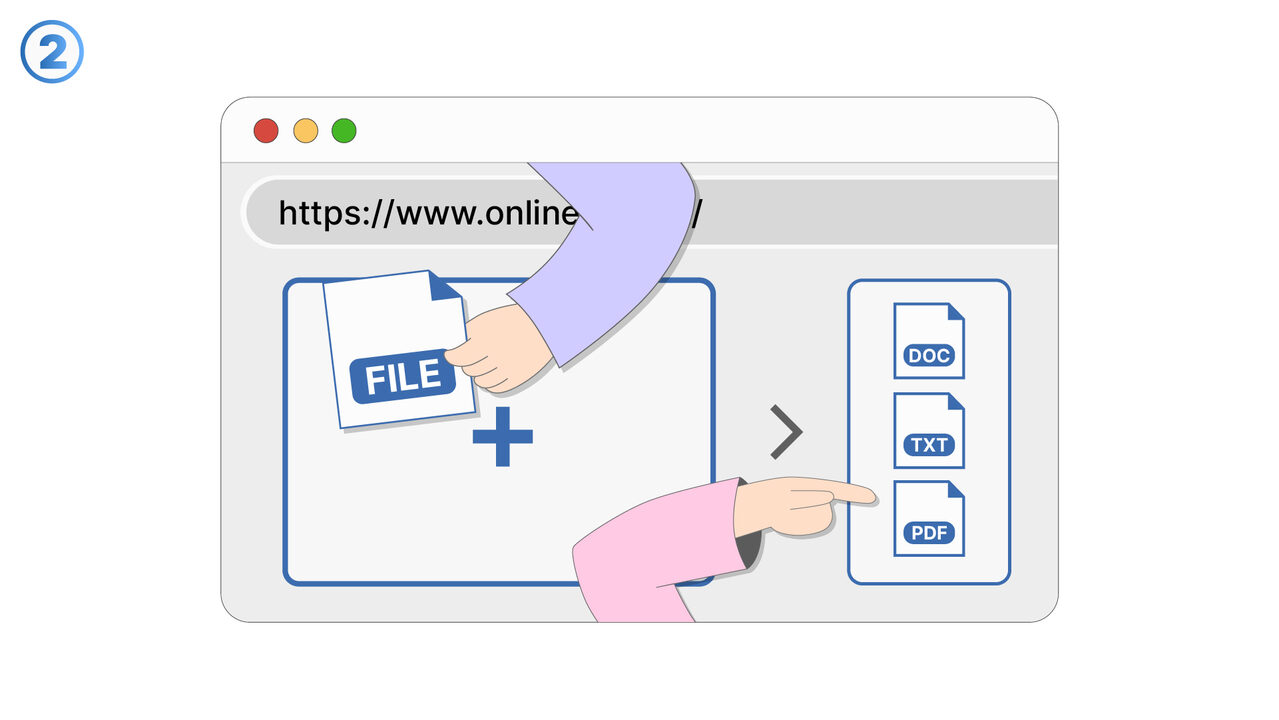
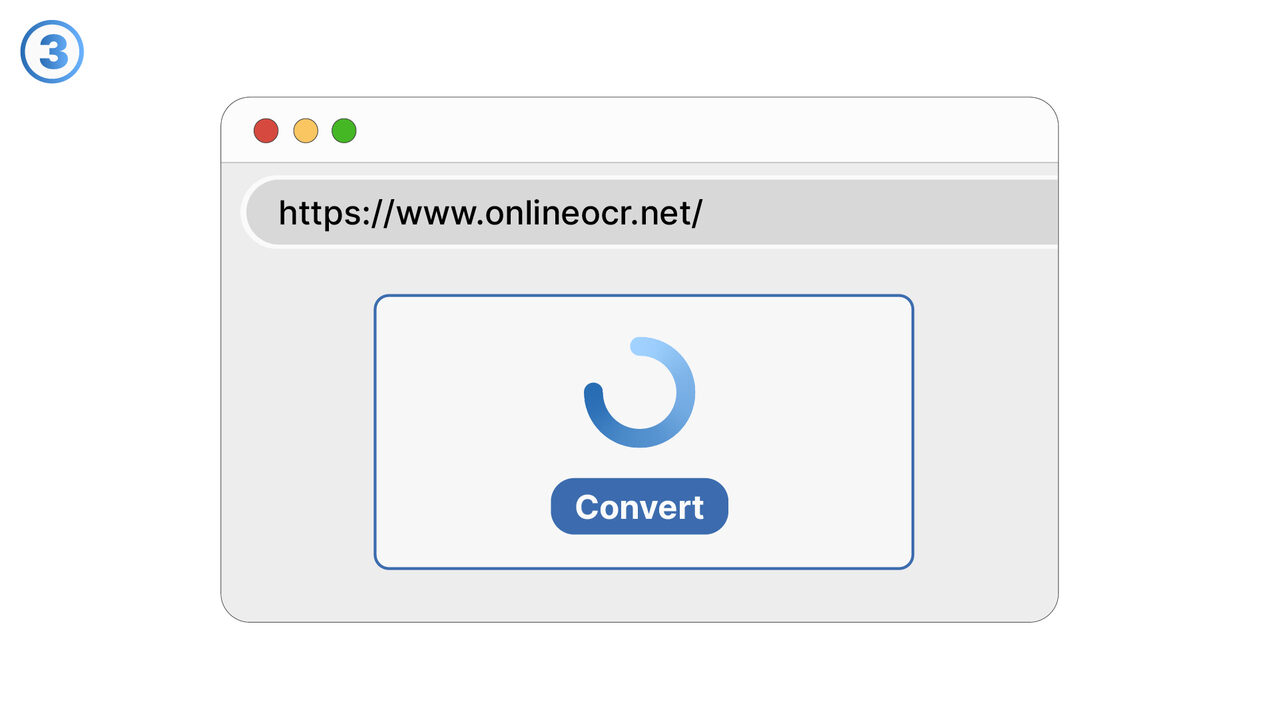
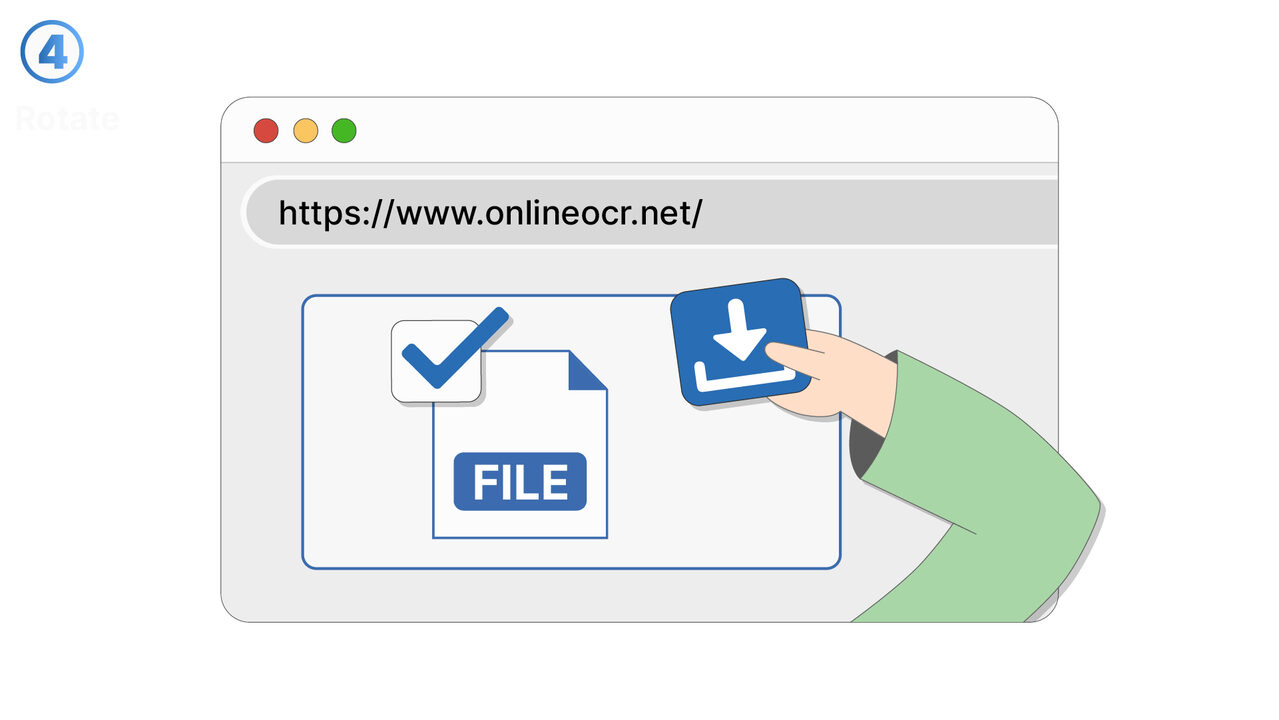
Løsningen
Gratis Online OCR hjelper med å løse problemet med ikke-søkbare PDF-filer ved å bruke OCR-teknologi for å identifisere tekst i bilder og skannede dokumenter, og konvertere disse til redigerbare og søkbare formater. I tillegg digitaliserer det trykte tekster for å kunne redigere, indeksere og søke i dem. Det muliggjør en enkel og rask konvertering av bilder til digitalt tekstformat. Med disse funksjonene kan verktøyet spare betydelig tid og forenkle oppgaven med å søke gjennom store dokumenter etter spesifikk informasjon.
Ekstern ressurs
https://www.onlineocr.net
Bruk dette verktøyet som en løsning på følgende problemer
- Jeg kan ikke redigere teksten i mitt skannede dokument.
- Jeg sliter med å konvertere skannede og trykte tekster til et redigerbart format.
- Jeg har problemer med å trekke ut tekst fra skannede dokumenter og bilder og konvertere den til et redigerbart format.
- Jeg må konvertere skannede dokumenter og bilder på flere språk til redigerbar tekst.
- Jeg trenger en enkel og rask metode for å trekke ut tekstinformasjon fra skannede dokumenter, PDF-er og bilder, og gjøre dem redigerbare.
- Jeg må konvertere bilder til et søkbart og redigerbart tekstformat.
- Jeg har problemer med å digitalisere trykt tekst i dokumentene og bildene mine, og gjøre dem søkbare.
- Jeg leter etter et verktøy for å konvertere mine PDF-dokumenter til redigerbare og søkbare formater.
- Jeg har problemer med å konvertere skannede dokumenter og bilder til redigerbar tekst.
Kjenner du en bedre løsning? La oss vite det.
Hvis du kjenner et verktøy eller en tilnærming som kan hjelpe folk med å løse et problem vi ikke har dekket ennå, vil vi gjerne høre om det.