Jeg har problemer med å digitalisere trykt tekst i dokumentene og bildene mine, og gjøre dem søkbare.
Løst av Gratis Online OCR
Problemet
Utfordringen består i å digitalisere trykket tekst fra dokumenter og bilder, og gjøre det søkbart. Denne prosessen kan være tidkrevende og kjedelig, spesielt hvis dokumentene og bildene inneholder en stor mengde informasjon. Manuell datainngang kan føre til feil og er ofte ikke effektiv. Dessuten kan det være vanskelig å trekke ut trykket tekst fra dokumenter på forskjellige språk. Så spørsmålet er derfor om en enkel, rask og pålitelig metode for teksterkjennelse og -ekstraksjon fra skannede dokumenter, PDFer og bilder.
Skjermbilder
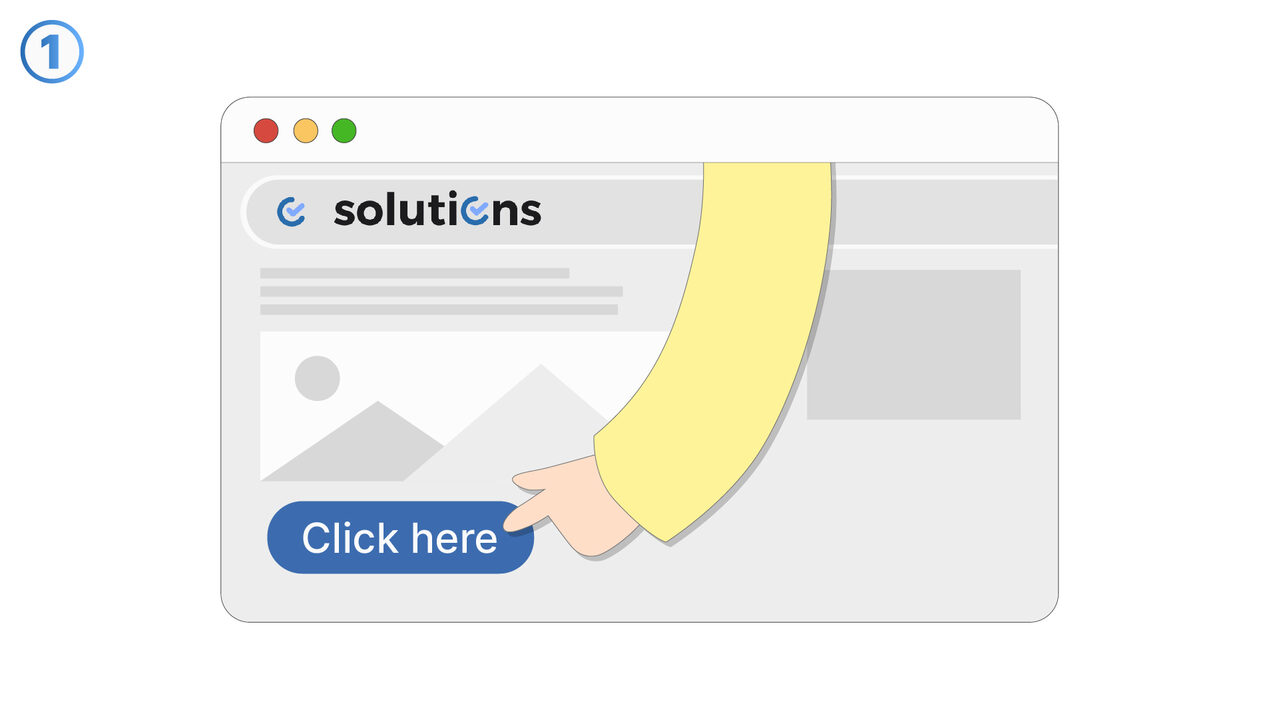
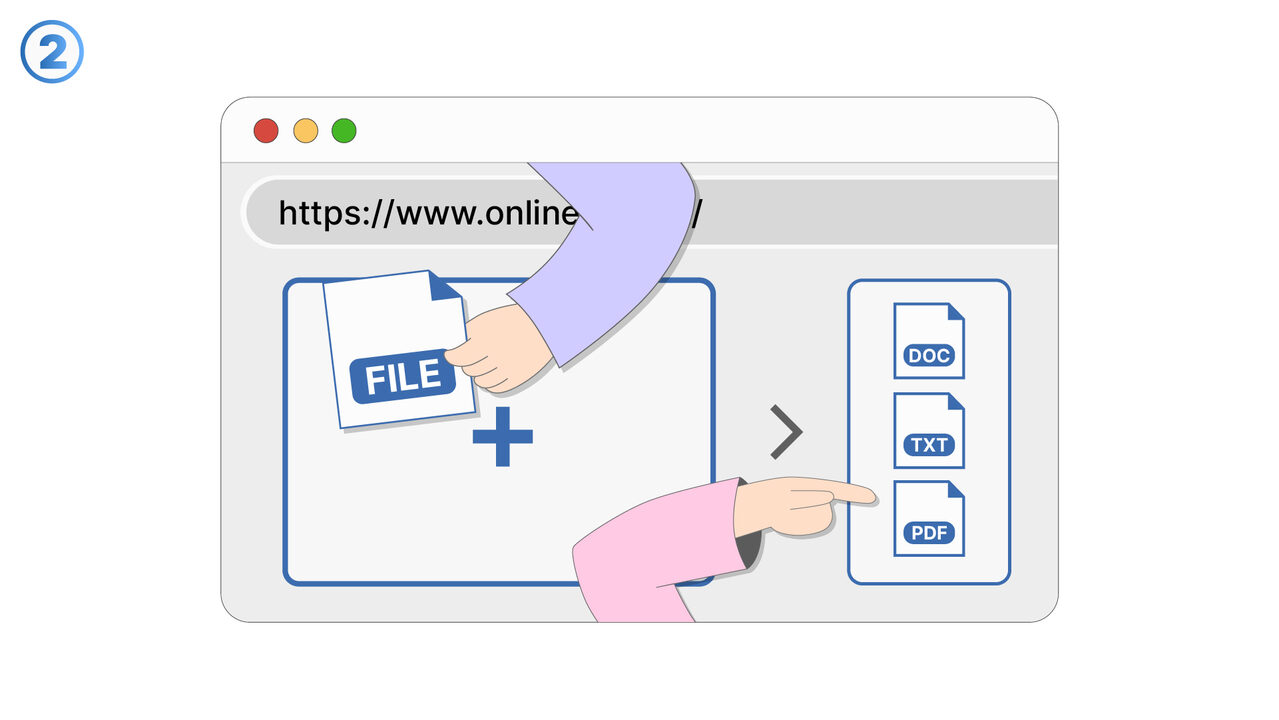
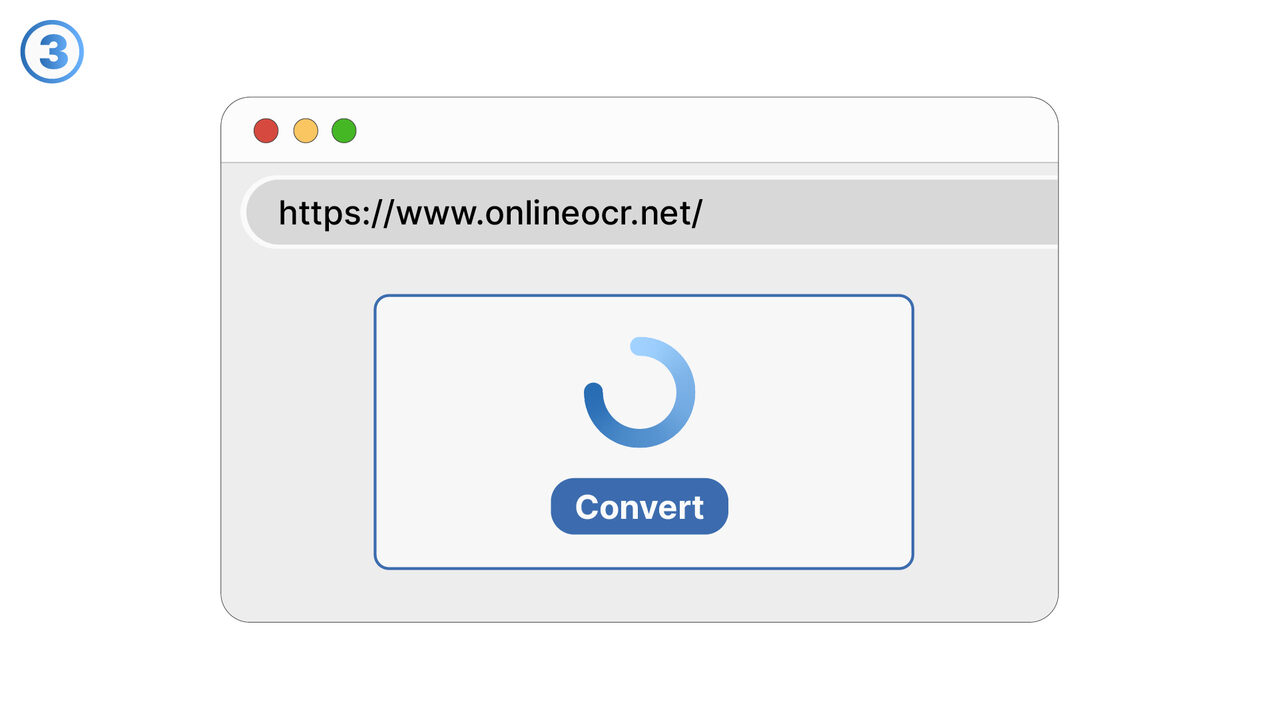
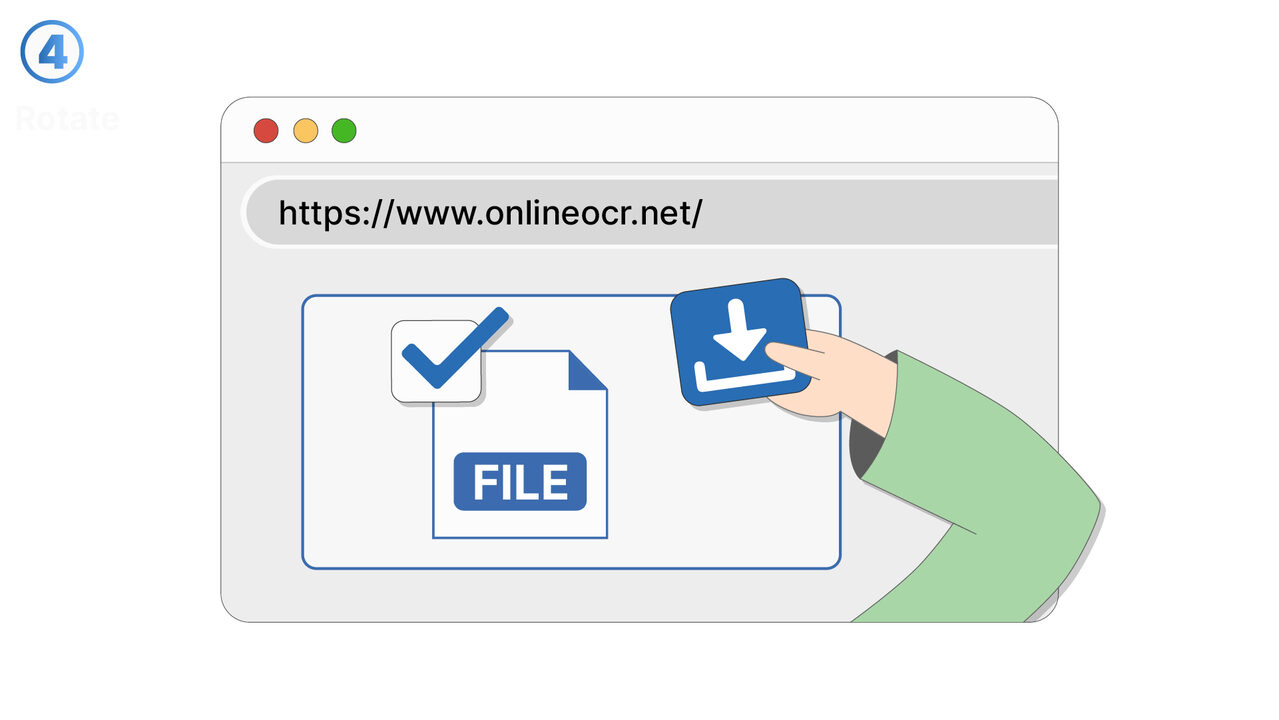
Løsningen
Gratis Online OCR revolusjonerer tekstgjenkjenning i skannede dokumenter, PDFer og bilder. Det gjenkjenner tekster ved hjelp av sin OCR-teknologi og konverterer disse til redigerbare og søkbare formater som DOC, TXT eller PDF. Samtidig reduserer det tidskrevende manuell datainngang og minimerer potensielle feilkilder. Selv dokumenter og bilder med en stor mengde informasjon eller i forskjellige språk, håndterer verktøyet uten problemer. Dette resulterer i en enkel, rask og pålitelig metode for tekstgjenkjenning og -ekstraksjon. Dette verktøyet er derfor ideelt for de som regelmessig må jobbe med skannede bilder og trenger digital tekstinformasjon.
Ekstern ressurs
https://www.onlineocr.net
Bruk dette verktøyet som en løsning på følgende problemer
- Jeg kan ikke redigere teksten i mitt skannede dokument.
- Jeg kan ikke søke gjennom teksten i et PDF-dokument og trenger en løsning for dette.
- Jeg sliter med å konvertere skannede og trykte tekster til et redigerbart format.
- Jeg har problemer med å trekke ut tekst fra skannede dokumenter og bilder og konvertere den til et redigerbart format.
- Jeg må konvertere skannede dokumenter og bilder på flere språk til redigerbar tekst.
- Jeg trenger en enkel og rask metode for å trekke ut tekstinformasjon fra skannede dokumenter, PDF-er og bilder, og gjøre dem redigerbare.
- Jeg må konvertere bilder til et søkbart og redigerbart tekstformat.
- Jeg leter etter et verktøy for å konvertere mine PDF-dokumenter til redigerbare og søkbare formater.
- Jeg har problemer med å konvertere skannede dokumenter og bilder til redigerbar tekst.
Kjenner du en bedre løsning? La oss vite det.
Hvis du kjenner et verktøy eller en tilnærming som kan hjelpe folk med å løse et problem vi ikke har dekket ennå, vil vi gjerne høre om det.